One of the great joys of working with two talented post-docs in the research group – Mike Stout and Mudassar Iqbal – as well as a great collaboration with Theodore Kypraios, is that they are often one step ahead of me and I am playing catch-up. Recently, Theo has discussed with them how to estimate the error variance associated with the data used in Metropolis-Hastings MCMC simulations.
The starting point, usually, is that we have some data, let us say  for
for  , and a model – usually, in our case, a dynamical system – which we are trying to fit to the data. For any given set of parameters
, and a model – usually, in our case, a dynamical system – which we are trying to fit to the data. For any given set of parameters  , our model will provide estimates for the data points that we will call
, our model will provide estimates for the data points that we will call  . Now, assuming uniform Gaussian errors, our likelihood function
. Now, assuming uniform Gaussian errors, our likelihood function  looks like:
looks like:

where 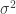 is the error variance associated with the data. Now, when I first started using MCMC, I naively thought that we could use values for provided by our experimental collaborators, and so we could use different values of according to how confident our collaborators were in the measurements, equipment etc. What I found in practice was that these values rarely worked (in terms of convergence of the Markov chain) and we have had to make up error variances using trial and error.
is the error variance associated with the data. Now, when I first started using MCMC, I naively thought that we could use values for provided by our experimental collaborators, and so we could use different values of according to how confident our collaborators were in the measurements, equipment etc. What I found in practice was that these values rarely worked (in terms of convergence of the Markov chain) and we have had to make up error variances using trial and error.
So I was delighted when I heard that Theo had briefed both Mike and Mudassar about a method for estimating the error variance as part of the MCMC. Since I have not tried it before, I thought I would give it a go. I am posting the theory and some of my simulations, which are helpful results.
Theory
The theory behind estimating is as follows. First, set

We can then re-write the likelihood, now for the model parameters and also the unknown value  , as
, as

Now observe that this has the functional form of a Gamma distribution for , as the p.d.f. for a Gamma distribution is given by:

So if we set a prior distribution for as a Gamma distribution with parameters 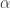 and
and 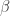 , then the conditional posterior distribution for is given by:
, then the conditional posterior distribution for is given by:

We observe that this is itself a Gamma distribution, with parameters  and
and  . Thus the parameter can be sampled with a Gibbs step as part of the MCMC simulation (usually using Metropolis-Hastings steps for the other parameters).
. Thus the parameter can be sampled with a Gibbs step as part of the MCMC simulation (usually using Metropolis-Hastings steps for the other parameters).
Simulations
The simulations I have run are with a toy model that I use a great deal for teaching. Consider a constitutively-expressed protein that is produced at constant rate 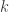 and degrades (or dilutes) at constant rate
and degrades (or dilutes) at constant rate  per protein. A differential equation for protein concentration
per protein. A differential equation for protein concentration  is given by:
is given by:

This ODE has the closed form solution:

where  is the concentration of protein at
is the concentration of protein at 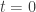 . For the purposes of MCMC estimation, mixing is improved by setting
. For the purposes of MCMC estimation, mixing is improved by setting  so that the closed form solution is:
so that the closed form solution is:

Some data I have used for teaching purposes comes from the paper Kim, J.M. et al. 2006. Thermal injury induces heat shock protein in the optic nerve head in vivo. Investigative ophthalmology and visual science 47: 4888-94. The data is quantitative Western blots of Hsp70 in the optic nerve of rats, as induced by laser damage. (Apologies for the unpleasantness of the experiment):
| Time / hours |
Protein / au |
| 3 |
1100 |
| 6 |
1400 |
| 12 |
1700 |
| 18 |
2100 |
| 24 |
2150 |
The aim is to use a Metropolis-Hastings MCMC, together with a Gibbs step for the parameter, to fit the data. The issue that immediately arises is how to set the parameters and . This may seem arbitrary, but it is already better than choosing a value for , as the Gamma distribution will exploring of that parameter. For my first simulation, I thought that  would be sensible (this turned out to be a remarkably good choice, as we will see). So I set
would be sensible (this turned out to be a remarkably good choice, as we will see). So I set 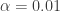 and
and  and lo and behold, the whole MCMC worked beautifully. (Incidentally, I used independent Gaussian proposals for the other three parameters, with standard deviations of 100 for the and
and lo and behold, the whole MCMC worked beautifully. (Incidentally, I used independent Gaussian proposals for the other three parameters, with standard deviations of 100 for the and  and standard deviation of 0.01 for . These parameters were forced to be positive – Darren Wilkinson has an excellent post on doing that correctly. Use of log-normal proposals in this case leads to very poor mixing, with the chain taking some large excursions for the and parameters).
and standard deviation of 0.01 for . These parameters were forced to be positive – Darren Wilkinson has an excellent post on doing that correctly. Use of log-normal proposals in this case leads to very poor mixing, with the chain taking some large excursions for the and parameters).

The median parameter values are  ,
,  ,
,  and
and  . The latter corresponds to
. The latter corresponds to  . With these values, we can see a good fit to the data: below are plotted the data points (in red), the best fit (with median parameter values) in blue, and model predictions from a random sample of 50 parameter sets from the posterior distribution in black.
. With these values, we can see a good fit to the data: below are plotted the data points (in red), the best fit (with median parameter values) in blue, and model predictions from a random sample of 50 parameter sets from the posterior distribution in black.

Considerations
However, some questions obviously arise: how sensitive is this procedure to choices of and ? I will confess: I use Bayesian approaches fairly reluctantly, being more comfortable with classical frequentist statistics. What I like about Bayesian approaches are firstly the description of unknown parameters with a probability distribution, and secondly the availability of highly effective computer algorithms (i.e. MCMC). What makes me uncomfortable is the potential for introducing bias through the prior distributions. So I have carried out some investigations with different values of and . In particular, I wanted to know: (i) what happens if I keep the mean (equal to  ) the same but vary the parameters? (ii) what happens if I vary the mean of the distribution? The table below summarizes positive results:
) the same but vary the parameters? (ii) what happens if I vary the mean of the distribution? The table below summarizes positive results:
| alpha |
beta |
P0 |
P1 |
gamma |
sigma |
| 0.01 |
100 |
786 |
2526 |
0.0686 |
90.6 |
| 1 |
10000 |
747 |
2428 |
0.0795 |
98.0 |
| 0.0001 |
1 |
797 |
2533 |
0.0681 |
96.3 |
| 0.1 |
10 |
822 |
2603 |
0.0623 |
97.9 |
| 0.001 |
1000 |
760 |
2455 |
0.0758 |
94.8 |
| 1 |
1 |
792 |
2539 |
0.0676 |
64.9 |
| 0 |
0 |
805 |
2565 |
0.0653 |
98.3 |
As you can see (please ignore the last line for now), the results are robust to a very wide range of and , even producing a good estimate for 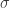 when that estimate is a long way from the mean of the prior distribution. But then we can make the following observation. Consider the sum of squares for a ‘best-fit’ model, for example using the parameters for the first row (this is 12748). So as long as
when that estimate is a long way from the mean of the prior distribution. But then we can make the following observation. Consider the sum of squares for a ‘best-fit’ model, for example using the parameters for the first row (this is 12748). So as long as  and
and  , the prior will introduce very little bias. But if you try to use values of and especially very much larger than an estimated sum of squares from well-fitted model parameters, then things might go wrong. For example, when I set
, the prior will introduce very little bias. But if you try to use values of and especially very much larger than an estimated sum of squares from well-fitted model parameters, then things might go wrong. For example, when I set  and
and  then my MCMC did not converge properly.
then my MCMC did not converge properly.
This leads to my final point, and the final row in the table. Would it be possible to remove prior bias altogether? If you look at the marginal posterior for , we observe that if we set  , we obtain a Gamma distribution, whose mean is precisely the error variance, as, in this case,
, we obtain a Gamma distribution, whose mean is precisely the error variance, as, in this case,

The algorithm should work perfectly well sampling from this Gamma distribution, and indeed it does, producing comparable results to when an informative prior is used.
Conclusions
In summary, I am happy to conclude that this method is good for estimating error variance. Clear advantages are:
- It is simple to implement and fairly fast to run – adding a Gibbs step is no big deal.
- It is clearly preferable to making up a fixed number for the error variance – which was what we were doing before.
- The prior parameters allow you to make use of information you might have from experimental collaborators on likely errors in the data.
- The level of bias from the priors is relatively low, and can be eliminated altogether.


